Language Detector Project Summary
Goal
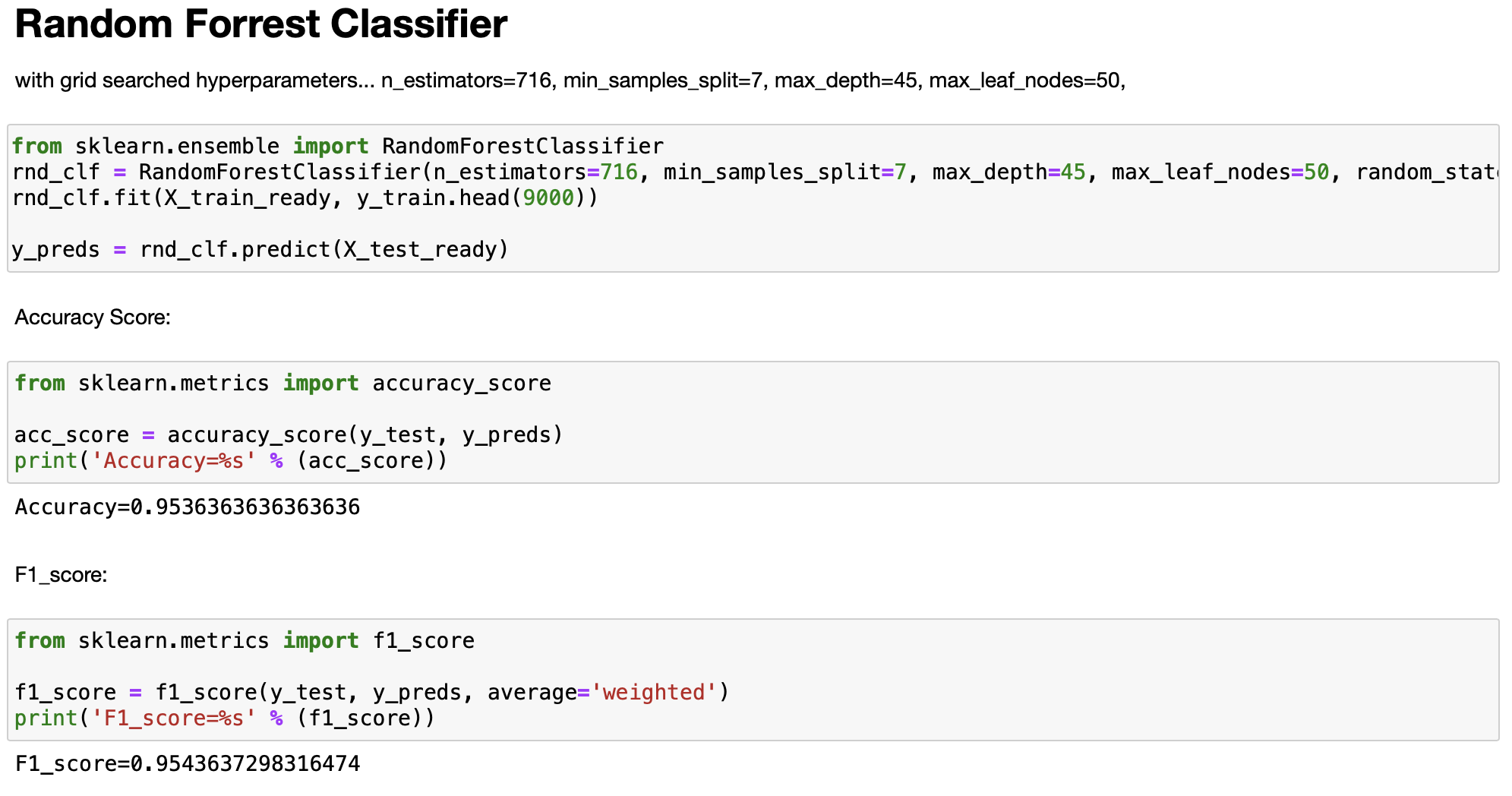
Our goal was to train a model that could detect the language of user input with an accuracy score of at least 90%, using either a decision tree, random forest, adaboost, or gradient boosting classifier.
Method
We decided to identify languages by individual characters. We created a function that goes through a dataframe of text and calculates the fraction of number of times a specific character appears divided by the total number of characters in the text. The function accepts a dataframe and a list of characters, then goes through the list of characters, finds the fraction of occurrence, and sticks the value into a dataframe which would look something like this:
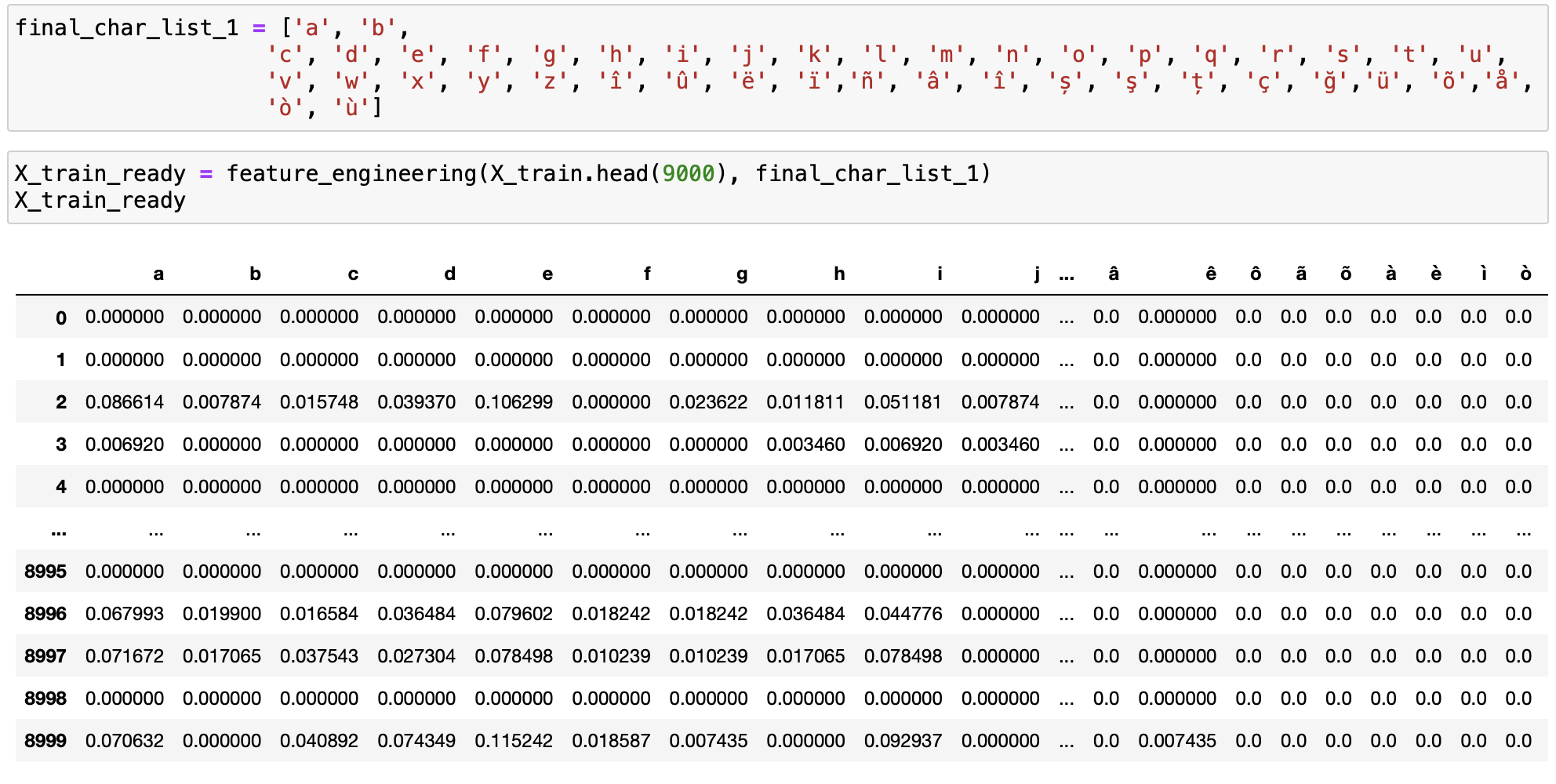
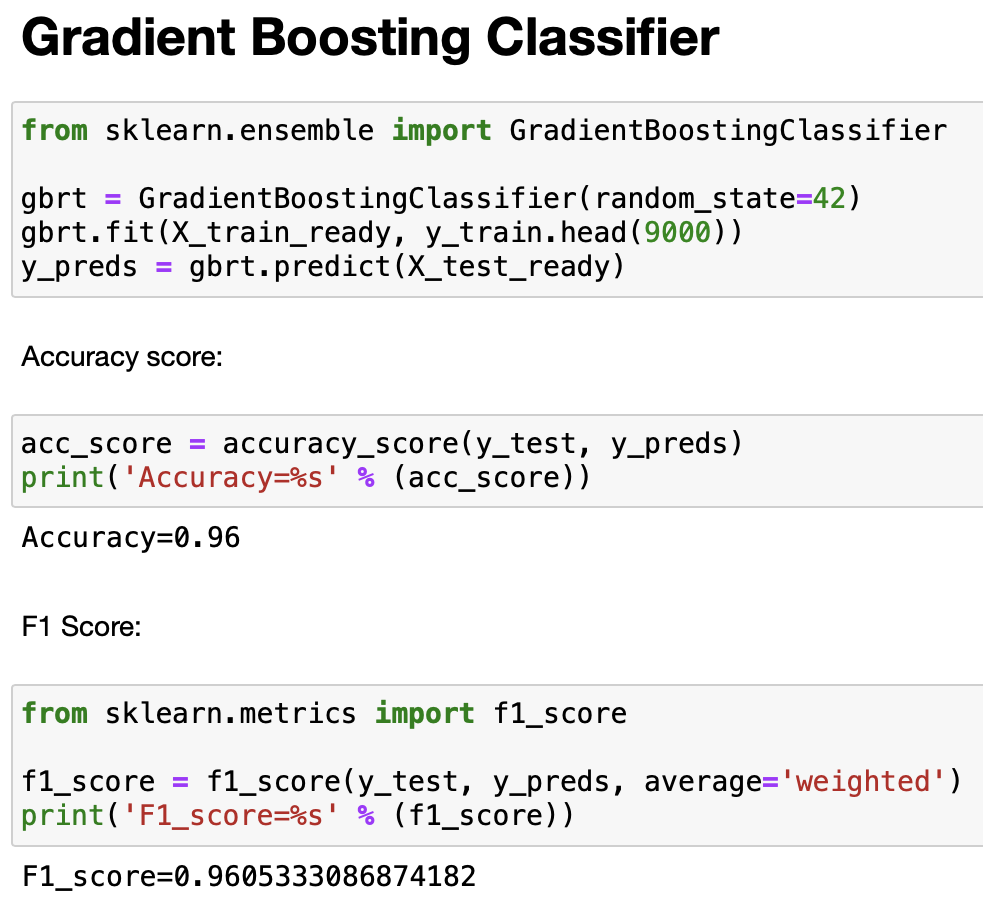
We then can send this dataframe and the y_train values to the .fit() method, which trains a model on the data. After trying different types of models with varying numbers of characters, groups of characters, we found that a gradient boosting classifier has the highest accuracy on the training and test set, followed by a random forest, then an adaboost classifier, and lastly a decision tree. Additionally, we discovered that the highest accuracy achieved, 96%, was achieved by finding the frequency of individual characters of romance languages, and by finding the frequency of groups of characters from non-romance languages like Chinese, Japanese, Pushto, Tamil, etc.
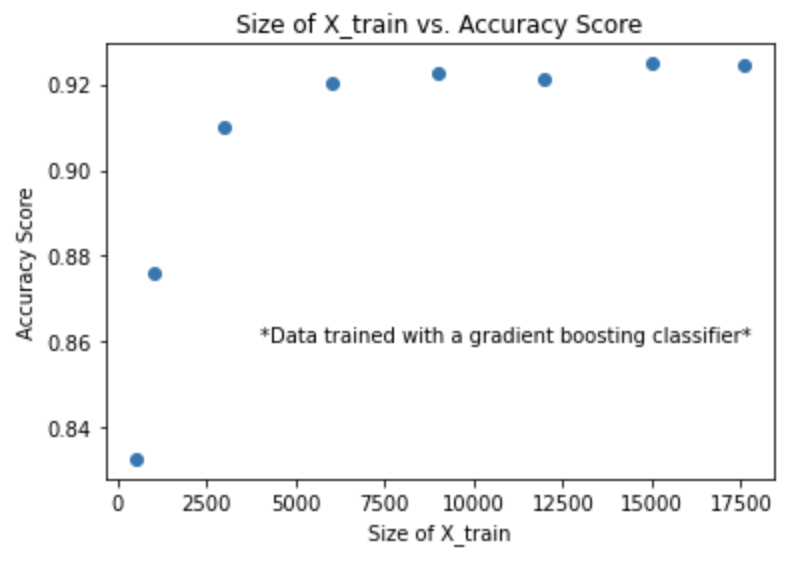
We found that 9,000 out of the 17,600 rows of text data was optimal when training the model, rather than the full size of X_train, which would take longer and create an excessive amount of features.
Further Investigation
If we were to work more on this project and hope to increase the accuracy score, searching for common words, common bi-grams (like in english: at, ea, ch, sh, th), or increasing the list of characters for languages that have thousands of characters like Chinese, Japanese, etc. We think these would increase the success of our project, possibly increasing the accuracy score from 96% to about 98% or 99%.